
The next wave of security threats are upon us: Here’s what you need to know
Sponsored By

![]()
InfoWorld
11/05/09
You'll want to be familiar with the Apache Hadoop framework before you jump into Elastic MapReduce. It doesn't take long to get the hang of it, though. Most developers can have a MapReduce application running within a few hours.
Have you got a few hundred gigabytes of data that need processing? Perhaps a dump of radio telescope data that could use some combing through by a squad of processors running Fourier transforms? Or maybe you're convinced some statistical analysis will reveal a pattern hidden in several years of stock market information? Unfortunately, you don't happen to have a grid of distributed processors to run your application, much less the time to construct a parallel processing infrastructure.
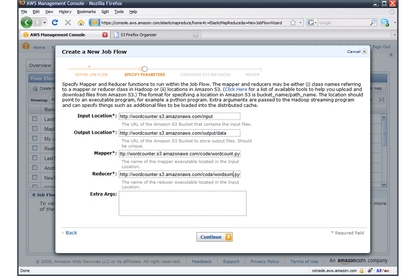
Well, cheer up: Amazon has added Elastic MapReduce to its growing list of cloud-based Web services. Currently in beta, Elastic MapReduce uses Amazon's Elastic Compute Cloud (EC2) and Simple Storage Service (S3) to implement a virtualized distributed processing system based on Apache Hadoop.
Hadoop's internal architecture is the MapReduce framework. The mechanics of MapReduce are well documented in a paper by J. Dean and S. Ghemawat [PDF], and a full treatment is beyond the scope of this article. Instead, I'll illustrate by example.
Suppose you have a set of 10 words and you want to count the number of times those words appear in a collection of e-books. Your input data is a set of key/value pairs, the value being a line of text from one of the books and the key being the concatenation of the book's name and the line's number. This set might comprise a few megabytes big -- or gigabytes. MapReduce doesn't much care about size.
You write a routine that reads this input, a pair at a time, and produces another key/value pair as output. The output key is a word (from the original set of 10) and the associated value is the number of times that word appears in the line. (Zero values are not emitted.) This routine is the map part of map/reduce. Its output is referred to as the intermediate key/value pairs.
The intermediate key/value pairs are fed to another function (another "step" in the parlance of MapReduce). For this step, you write a routine that iterates through the intermediate data, sums up the values, and returns a single pair whose key is the word and whose value is the grand total. You don't have to worry about grouping the results of like keys (i.e., gathering all the intermediate key/values for a given word), because Hadoop does that grouping for you in the background.
What's new, plus best mac-related tips
and tricks

The latest business news, reviews, features and whitepapers

Watch our video news and reviews from around the world
Comprehensive buying guides, features, and step-by-step articles

Aruba Instant On AP11D

Set up is effortless.
Aruba Instant On AP11D

The strength of the Aruba Instant On AP11D is that the design and feature set support the modern, flexible, and mobile way of working.
Aruba Instant On AP11D

Aruba backs the AP11D up with a two-year warranty and 24/7 phone support.
Dynabook Portégé X30L-G

Ultimately this laptop has achieved everything I would hope for in a laptop for work, while fitting that into a form factor and weight that is remarkable.
MSI P65

This smart laptop was enjoyable to use and great to work on – creating content was super simple.
MSI GT76

It really doesn’t get more “gaming laptop” than this.